Classification of logical data models implemented by contemporary DBMS
Classification of logical data models implemented by contemporary DBMS
Abstract
Apart from relational model, many contemporary DBMS implement different data models, including extensions of relational ones. Most of DBMS implement also multiple data models, and are so called “multi-model”. However, there is no commonly used classification of actual data models that is a disorientating factor for database users: engineers, students, teachers, analysts, etc. This article contains common terms and definitions as well as the history of earlier model classification proposed by other experts in the database domain since the 1970s. Developing the graph-based and set-based classification approach, and classical hierarchy-network-relational triad, the article proposes an improved two-axis data model classification including new semi-structured ones as well as examples of DBMS implementing these models.
1. Introduction
Data models are fundamental entities that provide abstraction for DBMS (Data Base Management System). A DBMS is the software that handle all access to the database
. Any DBMS implements one or more data models corresponding to the datalogical modeling level.The concepts of datalogical and infological data models were introduced by B. Langefors. A user-oriented description is called the infological realm of data modeling. The mapping of basic infological concepts into a corresponding computer representation is called the datalogical realm of data modeling
. According to the ANSI/SPARC three-level architecture , the datalogical models correspond also to the conceptual level.To resolve this collision, J. Zachman tried to separate clearly conceptual, logical, and physical levels of data in models .
Modern computing foundations include the topic of database management; database design and data-centered approach are the important parts of software design strategies and methods
, , .This article is focused on logical level data models implemented by DBMS.
2. Main part
2.1. Data model definitions
A data model can be defined as a combination of three components
:1. A collection of data structure types.
2. A collection of operators or inferencing rules, which can be applied to any valid instances of the data types listed in (1), to retrieve or derive data from any parts of those structures in any combinations desired.
3. A collection of general integrity rules, which implicitly or explicitly define the set of consistent database states or changes of state, or both.
Another term definition is “A data model is a collection of conceptual tools for describing data, data relationships, data semantics, and consistency constraints”
.Data models are often confused with data (database) structural schemes. In fact, a model is an abstraction tool whereas a scheme is a result produced by used tool. For example, a relational database scheme is a result of modeling that uses the relational data model. In the software engineering practice, a database scheme is called also a database model to distinguish them from DBMS physical schemes implementing namespaces or security accessors.
2.2. Existing classifications
As of 1979, some 40 or more data models (mostly incomplete) have been proposed for the management of formatted data
, , .The classical approach has been suggested by C. Date in the first edition of his book
published in 1975. The approach separates data models in three categories:– hierarchical model;
– network model;
– relational model.
This classification has been largely reused in the study books on data management since the middle of 1970th and up to 2000th
, , . In the last editions of his book, C. Date writes about the hierarchical and network models: "We do not discuss these categories in detail in this book because — from a technological point of view, at least — they must be regarded as obsolete" .However, since the 1990th and early 2000th many non-relational data structures and models was introduced and re-introduced in different DBMS. There are several important reasons
, , , , :– dominating of object-oriented approach and impedance mismatch of object-relational mapping;
– evolution of OLAP (Online Analytical Processing) DBMS;
– evolution of Internet/Web data;
– reintroducing of VLDB (Very Large Databases) storage and analysis as "Big Data".
For example, the authors of "Database System Concepts"
have introduced the following new categories apart the relational one:– relational model;
– entity-relationship model;
– semi-structured data model;
– object-based data model.
M. Stonebraker and J.M. Hellerstein
have suggested the following data models in the context of their historical epochs:– hierarchical (IMS): late 1960’s and 1970’s;
– network (CODASYL): 1970’s;
– relational: 1970’s and early 1980’s;
– entity-Relationship: 1970’s;
– extended Relational: 1980’s;
– semantic: late 1970’s and 1980’s;
– object-oriented: late 1980’s and early 1990’s;
– object-relational: late 1980’s and early 1990’s;
– semi-structured (XML): late 1990’s to the present.
As one can see, the categorizations mentioned above:
1. Confuse data models of different levels. For example, ER (entity-relationship) was suggested in 1976
as a conceptual model, and as a "unified view of data" which allows the modeling of underlying relational and other logical database models.2. Do not take in account the mathematical basics like the graph theory or the set theory.
3. Do not regard schemaless/schemafull approach out of scope of semi-structured models. For example, XML data model without a schema can be considered as a semi-structured but the simple adding of an XML schema makes the model fully structured.
2.3. Suggested classification principles
Database systems can be conveniently categorized according to the data structures and operators they present to the user
. However, the data structures and operations may be considered also as elements of the model which are based on some formalism or a theory.2.3.1. Formalism of data models
The first classification axis is the theoretical basis, or the formalism which a data model is based on. The following formalisms are used since first DBMS had been developed in 1960’s:
– graph theory;
– set theory;
– higher-order function notion from the category theory (map).
Data models based on the graph theory have the following qualities:
1. Each data item is represented as a record of some type. In the modern world an object with properties may be used instead.
2. Each record can be explicitly linked to one or more records, for example, using physical pointers; the model is called "hierarchical" when cyclic links are disabled.
3. To access a data item the user should specify the path containing established links.
Data models based on the set theory have the following characteristics:
1. Each data item called "a tuple" is an ordered set of elements of different data types.
2. There are no explicit links between tuples
3. To access one or more data items user should specify an operation on the data set; for example, intersect two set of tuples
The maps are well known since introducing in the LISP programming language in 1958
. The following qualities are proper to maps :1. Each data item called "a value" may have any data type.
2. There is no explicit or implicit links between items.
3. To access an item user should specify other value called "a key". Every key can be associated with only one value.
Table 1 - Principal distinctions between data model classes
Comparing element | Graph models | Set-oriented models | Map based models |
Data structure type of an item | Record | Tuple | Value |
Links between data items | Explicit | Implicit (set operations) | Not supported |
Data integrity rules | Supported | Supported | Not supported (*) |
Access to a data item | Explicit path (trajectory) | Implicit (set operations) | Explicit (by key) |
Storing of data items | Ordered | Not ordered | Ordered |
Output of data items | Ordered | Not ordered (**) | Not ordered |
Note: * – may be partially supported when introducing constraints on values and types; ** – an ordered set can be produced with some specific operations; for example, ORDER BY in SQL but the storage does not respect any item order
2.3.2. Structuring level classes
The second axis identifies the class of data structuring level supported by a data model:
– structured data models;
– semi-structured data models;
– non-structured data models (out of subject).
In the structured data model, all data items should have a predefined type including complex types. For example, records of the same type should have the same set of fields
.Semi-structured data model allows the specification of data items where individual items may do not have a type at all, or the items of the same type may have different structure
. For example, "flexible" records even being based on the same type, may have different fields.Non-structured data models are out of databases realm because of the database definition as a structured data storage
, , .2.4. Classifications
Axis 1: Formalism used
The following hierarchy seems to be good enough to include all widely used data models.
1) graph based models:
◦ Hierarchical model;
◦ Network model;
◦ Document-oriented;
◦ Object-oriented (data only);
◦ Graph model;
◦ RDF (Resource Description Framework)
.2) set oriented models:
◦ Relational;
◦ Multidimensional
;◦ Key-object
;3) map based models:
◦ Key-value
;◦ EAV/CR;
◦ Column store.
Axis 2: Structuring level
Only two classes are required to distinguish data models:
1. Structured data models (also called “schemafull”).
2. Semi-structured data models (“schemaless”).
Some data models allow to use both structured and semi-structured facilities. For example, XML, the modern document-oriented framework implementation, allows to define documents which are constrained by XML schema, as well as schemaless documents. Idem for JSON.
2.4.1. Classified DBMS examples
The following examples are based on a wide range of DBMS including multi-model ones, embedded, “on-premises” and cloud SaaS ones, commercial and open source ones etc. Some of DBMS like IBM IMS may be considered as discontinued but they are important at the historical perspective, and still using in business.
Table 2 - Classified DBMS examples
Formalism used | Structured | Semi-structured |
Graph based | ||
Hierarchical model | IMS, INES, Caché | LDAP, Windows registry, Caché |
Document-oriented | XML: CosmosDB, SQL Server, Oracle, BaseX, MarkLogic JSON: Dynamo, CosmosDB, MongoDB, CouchDB, PostgreSQL, Spark | |
Network model | IDS, Raima DB, Cronos |
|
Object-oriented | GemStone, Versant, DB4O |
|
Graph | Oracle, SQL Server | Neo4j |
RDF | Oracle |
|
Set-oriented | ||
Relational | DB2, Oracle, SQL Server, PostgreSQL, MySQL | Excel, Calc |
Multidimensional | SQL Server (MDX), Cognos, SAS | Caché |
Key-object | KeySQL |
|
Map based | ||
Key-value | Redis, Couchbase, InfinityDB, RocksDB, Tarantool, Windows INI files | |
EAV/CR | TrialDB, Magento | |
Column store | HBase, Cassandra, Riak | |
The classification may also be presented as a pie-chart diagram.
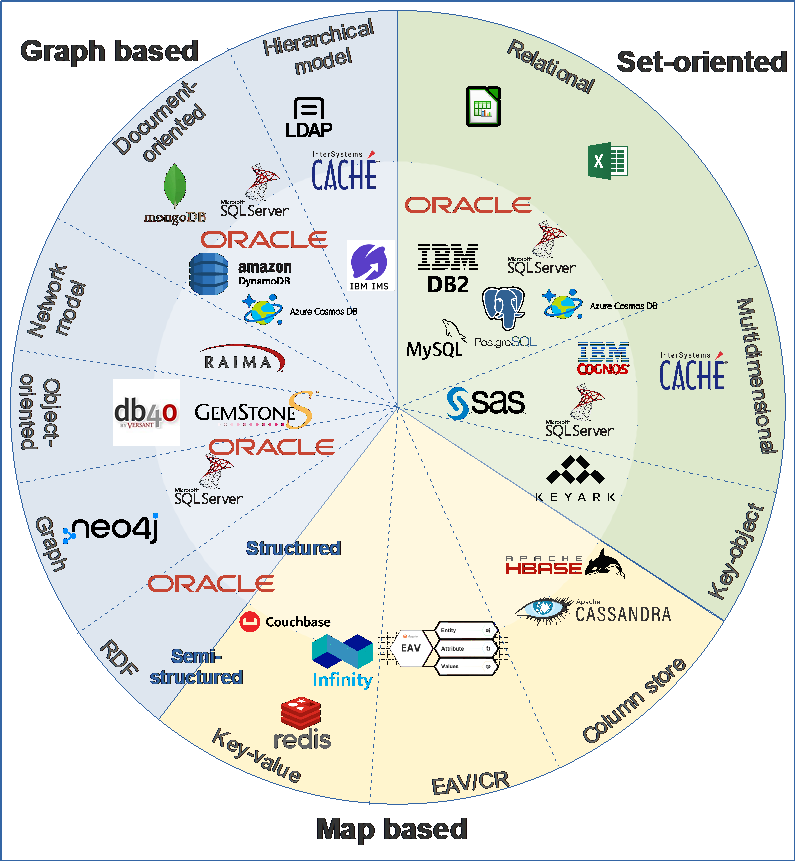
Figure 1 - Graphical representation of classified DBMS
Understanding and comparing supported data models may be a crucial factor on DBMS technical choice.
Different data models have their own limitations that may affect the efficiency of storing and querying the data (see more details on different models in the book
, ).For example, the multidimensional model may require massive recomputing when one of values has been changed. This wont be a good solution for transactional processing but will be for analytical one.
NoSQL models are indeed pre-relational, they are not closed under certain operations on the data. This means, you should write programs to extract the data instead of simple query pipelines as it is for SQL. That is why many NoSQL vendors is trying to add SQL-like query language on the top of existing low level scripting languages.
Data model classification is also useful when giving courses for students: we may concentrate on more abstract notions than the names and functions of different DBMS brands.
3. Conclusion
The proposed classification allows to understand better contemporary DBMS features, opportunities and constraints based on the used data model. In fact, many DBMS implement more than one data model to enhance the field of use.
Some buzzwords like “NoSQL” or “NewSQL” could be formalized as a subset of corresponding models. For example, “NoSQL” can be defined as both structured and semi-structured document-oriented model or, marginally, as all non-relational data models.
The proposed classification is not exhaustive but extensible and can include future data models.