Задача коммивояжёра с поворотными штрафами: постановка по тройкам вершин и алгоритмические схемы решения
Задача коммивояжёра с поворотными штрафами: постановка по тройкам вершин и алгоритмические схемы решения

Аннотация
В статье рассматривается классическая задача коммивояжёра (TSP) и её вариация для маршрутизации на графах с поворотными штрафами, когда стоимость маршрута зависит не только от выбранных рёбер, но и от последовательности двух смежных переходов (троек вершин). Данная постановка формализуется через функцию стоимости второго порядка и соотносится с квадратичной задачей коммивояжёра (QTSP) и угловой постановкой (angular TSP). Представлен теоретический обзор результатов по сложности, аппроксимациям и наиболее эффективным алгоритмическим подходам к TSP. Предложены две взаимодополняющие схемы решения turn-cost модели: точная MILP-формулировка с линеаризацией тройных переходов и стандартными ограничениями на подтуры для малых и средних размеров, а также масштабируемая эвристическая схема для больших графов, основанная на разрежении кандидатных рёбер, локальном поиске типа k-opt и инкрементальном пересчёте поворотной компоненты целевой функции. Обсуждаются вычислительные ограничения моделей, оценка роста числа учитываемых троек при разрежении и область применимости подходов для задач практической маршрутизации.
1. Введение
1.1. Актуальность и контекст
Задача коммивояжёра (TSP) является базовой моделью комбинаторной оптимизации и используется как эталон при развитии точных и эвристических методов решения NP-трудных задач. Современные обзоры подчёркивают, что даже при наличии сильных теоретических результатов (классические динамические схемы, аппроксимационные гарантии для метрических случаев, развитые MILP/branch-and-cut подходы) практическое масштабирование на сотни тысяч и миллионы узлов требует локального поиска, разрежения соседств и вычислительной инженерии.
В транспортных и навигационных приложениях стоимость движения часто зависит не только от ребра (j,k), но и от предыдущего шага (i,j): повороты создают задержки на перекрёстках, ограничения по радиусу и дополнительные риски манёвра. Это приводит к модели второго порядка, где вклад определяется тройками i→j→k, и требует корректной постановки и алгоритмической адаптации локального поиска, особенно при больших n.
1.2. Цель и вклад
Цель: формализовать TSP с поворотными штрафами и предложить вычислительно реализуемый метод решения, согласованный с масштабированием.
Основной вклад:
1. Модель Turn-TSP со стоимостью по тройкам и нормализацией поворотного штрафа (для интерпретируемости λ).
2. MILP-постановка с линеаризацией троек (для малых n/эталонных оценок).
3. Turn-aware эвристика: жадная инициализация второго порядка + локальный поиск 2-opt/k-opt по F с кандидатным разрежением и локальным пересчётом ΔF; монотонность обеспечивается правилом принятия ΔF<0.
4. Минимальная экспериментальная валидация на Rand2D и Grid инстансах, демонстрирующая эффект при λ>0.
2. Методы и принципы исследования
2.1. Постановка задачи: стоимость по тройкам и нормализация
Пусть задано множество вершин V={1,…,n} и базовые стоимости переходов djk≥0 (например, евклидово расстояние). Введём штраф поворота
Ищется гамильтонов цикл τ=(v1, …,vn, v1), минимизирующий
где индексы по модулю n, λ≥0 — вес важности поворотов,
Замечание 1 (Зачем нужна нормализация). Без нормализации масштаб P может доминировать или исчезать относительно D в зависимости от инстанса. Для углового штрафа удобно задавать
где θ — угол поворота в вершине j. Тогда λ становится сопоставимым между инстансами.
2.2. Пример: «стоимость поворота» через угол
Пусть вершинам соответствуют координаты
и положим
2.3. Точная MILP-модель (для малых n и эталонных оценок)
Введём бинарные переменные
Цель:
Ограничения «один вход/один выход»:
Линеаризация троек:
для всех допустимых i, j, k. Подтуры исключаются стандартными для TSP средствами (MTZ или плоскости отсечения); детальное обсуждение современных точных/аппроксимационных подходов и условий применимости приведено в обзорах.
Замечание 2. MILP с тройками имеет O(n3) переменных zijk в полном виде, поэтому применяется на малых n или при разрежении множества троек.
2.4. Эвристический метод: разрежение + второй порядок + turn-aware 2-opt
Метод ориентирован на масштабирование и опирается на ключевые принципы современных TSP-эвристик: локальный поиск, разрежение соседств и вычислительная эффективность.
2.4.1. Кандидатные множества (ограничение степени)
Для каждой вершины j строится список Cand(j) из K ближайших соседей по djk (обычно K∈[8,15], в частности K≤10 как практический компромисс). Далее при локальном поиске рассматриваются перестройки, использующие рёбра преимущественно из Cand(⋅), что уменьшает число проверяемых вариантов.
2.4.2. Начальное решение второго порядка
Начальный тур строится жадно по критерию второго порядка. При текущем конце тура (vt-1, vt) следующая вершина k выбирается как
Тем самым поворотный штраф учитывается уже на этапе построения.
2.4.3. Как модифицируется 2-opt под второй порядок: локальный ΔF
В классическом 2-opt выбираются две дуги (a, b) и (c, d) в текущем туре и выполняется перестройка, приводящая к замене на (a, c) и (b, d) (с разворотом промежуточного сегмента). Для цели первого порядка пересчитывается только вклад четырёх рёбер. Для цели второго порядка меняются также штрафы для троек около точек разрыва/склейки.
Ключевое наблюдение: 2-opt влияет на ограниченное число локальных троек возле вершин {a,b,c,d} (и их соседей по туру). Поэтому ΔF=ΔD+λΔP можно вычислять локально, без пересчёта всего F(τ), что критично по скорости.
Утверждение 1 (Монотонность). Если 2-opt/k-opt перестройка применяется только при ΔF<0, то последовательность F(τ) строго убывает; алгоритм завершается в локальном минимуме относительно выбранного класса перестроек.
2.5. Пояснение вычислительной сложности (что означают O(n2), O(nK), O(n3))
- Без разрежения: полный перебор 2-opt даёт O(n2) кандидатов на один «проход». Если при каждом кандидате пересчитывать F целиком за O(n), получится O(n3) на проход.
- С локальным ΔF: оценка одного кандидата делается за O(1) (константное число рёбер и локальных троек), поэтому полный 2-opt проход O(n2).
- С кандидатами размера K: перебор сокращается до порядка O(nK), а при локальном ΔF один проход становится O(nK). Именно поэтому ограничение степени (например, K≤10) практически значимо и объясняет наблюдаемое масштабирование.
3. Основные результаты
3.1. Экспериментальная постановка
Использованы два класса инстансов:
1. Rand2D_n: точки равномерно на [0,1]2, n∈{100,300,800}.
2. Grid_25x25: решётка 25×25 (625 вершин), как простой прокси «дорожной» структуры.
Базовая стоимость dij — евклидово расстояние. Штраф
- Baseline: Nearest Neighbor + 2-opt, оптимизирующие только D; затем вычисление F при разных λ.
- TurnAware: жадная инициализация по D+λP + turn-aware 2-opt по F с локальным ΔF и разрежением.
В качестве контрольной проверки при λ=0 оба метода должны совпадать по целевой функции, что и наблюдается.
3.2. Результаты (выдержка при λ=1)
Таблица 1 иллюстрирует характерный эффект: TurnAware уменьшает поворотную компоненту P и общую цель F; длина D может умеренно увеличиваться, что соответствует смыслу штрафов поворота.
Таблица 1 - Сравнение Baseline и TurnAware при λ=1,0
Инстанс | n | Fbase | Fturn | ΔF, % | Pbase | Pturn | ΔP, % |
Grid_25x25 | 625 | 2469,1 | 1286,3 | 47,9 | 1823,2 | 396,8 | 78,2 |
Rand2D_100 | 100 | 227,6 | 56,9 | 75,0 | 219,5 | 19,2 | 91,3 |
Rand2D_300 | 300 | 626,2 | 119,5 | 80,9 | 611,3 | 45,7 | 92,5 |
Rand2D_800 | 800 | 1667,9 | 234,8 | 85,9 | 1643,0 | 90,1 | 94,5 |
Примечание: цель F=D+λP
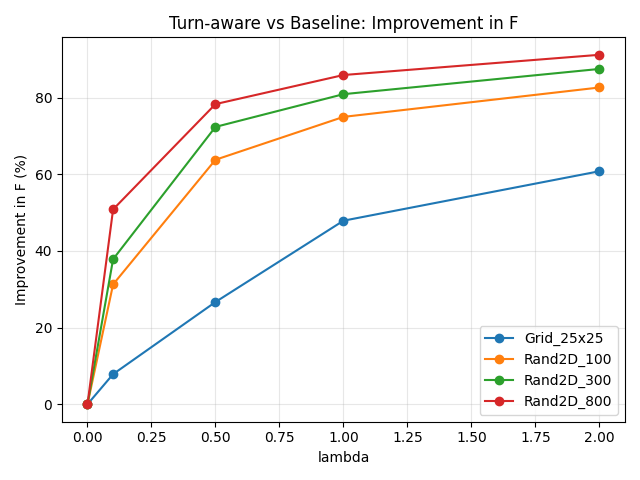
График зависимости эффекта от λ
TurnAware vs Baseline: улучшение по F=D+λP в зависимости от λ на Rand2D и Grid-инстансах.
3.3. Вычислительные затраты
Baseline заметно быстрее, так как оптимизирует только D и использует простой локальный критерий. TurnAware требует дополнительного времени на (i) построение второго порядка и (ii) оценку перестроек по F, однако разрежение и локальный ΔF делают метод практичным на сотнях и тысячах вершин, что согласуется с наблюдениями о масштабировании современных локальных эвристик.
4. Обсуждение
4.1. Интерпретация и практический смысл
Эксперименты показывают:
- При λ=0 методы совпадают (контроль корректности).
- При λ>0 TurnAware резко снижает P и тем самым F.
- Увеличение D при росте λ интерпретируется как компромисс: маршрут становится «плавнее» (меньше резких манёвров), что соответствует прикладным требованиям (время на поворот, безопасность, энергоэффективность).
4.2. Ограничения и минимальные улучшения «до принятия»
- Для редакционной версии желательно добавить 3–5 повторов на каждом инстансе (разные seed) и вывести среднее и стандартное отклонение по F; это недорого по времени, но заметно повышает убедительность.
- Для малых n (например, n≤60) можно решить MILP (или получить нижнюю оценку) и показать относительный разрыв (gap) эвристики; это закрывает вопрос о «точности» без громоздкой экспериментальной части.
5. Заключение
В статье предложена корректная постановка маршрутизации с поворотными штрафами как задачи второго порядка с целью F=D+λP, приведена MILP-модель с линеаризацией троек и разработан масштабируемый эвристический контур: жадная инициализация второго порядка и turn-aware локальный поиск 2-opt/k-opt на кандидатном пространстве с локальным пересчётом ΔF. Минимальная экспериментальная валидация на Rand2D и Grid инстансах демонстрирует существенное улучшение полной цели при λ>0 при приемлемых вычислительных затратах, что согласуется с общими принципами современных TSP-решателей (разрежение соседств, локальные перестройки, инженерия вычислений).